
I used a Logistic Regression model to predict with a 90% accuracy if a customer will continue to use this Audiobook app.
The Data:
The Customer data collected came in the form of the following features:
- id; int64
- Total Book Length (in minutes); float64
- Book Length Average (in minutes); int64
- Total Price of Books Purchased; float64
- Price Average of all Books Purchased; float64
- Left a Review (1 if yes, 0 if no); int64
- Review Score (0 to 10); float64
- Minutes listened; float64
- Minutes Completed; float64
- Support Request Made (1 if yes, 0 if no); int64
- Days Since Last Use Since First Purchase; int64

Preprocessing/Cleaning
The main issue regarding cleaning the data was handling missing values. I found the best method was to impute all missing values within the Review Score feature with the average score. Doing so helped in two ways:
My Preprocessing mostly consisted of balancing the dataset. the majority (over 80%) of the targets were 0. I kept this same ratio for all test, validation, and test datasets.
Modeling
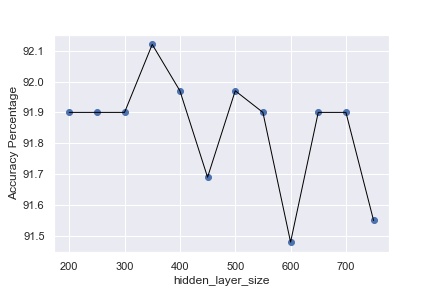
I used Tensorflow.keras to create my model. I also created a grid search to determine the optimal hidden layer size. the table on the right shows that a hidden layer size of 350 was the most optimal. Since all these models perform relatively well (over 90%), the main take away is that a hidden layer size of 350 not only gives us the best performing model but does so at the lowest computational cost.

Conclusion
Given our data, we can correctly predict whether 9 out of 10 individuals will continue to use this Audiobook platform.